Overview
After attending some lectures and reviewing several materials, it took me a considerable amount of time to grasp the basics of the exponential family and understand why and how they can be applied to GLMs (Generalized Linear Models). The fundamentals of GLMs will be thoroughly explained in this article.
We will begin with exponential families, then cover the basics of some machine learning algorithms (e.g. linear regression and logistic regression) and discover what they have in common. In the end, we will integrate all these concepts to derive a larger scale of models and to understand the reasons behind these desirable properties.
Note: This article is aimed at providing an overview, and some mathematical details are omitted. Readers can complete proofs on their own or by checking the material listed at the end of the article.
Exponential Family
The exponential familiy involves a set of probability
distributions whose probability density function can be
expressed as
Or in canonical form
Where
Properties
Property 1:
Property 2:
Property 3: Let
Property 4:
Linear Regression and Logisitic Regression
Now, let's review two of the most important algorithms in the field of machine learning: (ordinary) linear regression and logistic regression.
Linear Regression
Suppose we have
A common choice is to use normal distribution as the
probabilistic assumption. Here we assume
Take the derivatives of the log-likelihood and we will get
Let
So the update rule with gradient ascent is given by
Where
This update rule is computationally efficient and makes intuitive sense. Consider the following cases: - Case 1: The prediction is smaller than the target. Increase the parameter if the corresponding feature is positive, and vice versa. - Case 2: The prediction is larger than the target. Decrease the parameter if the corresponding feature is positive, and vice versa. - Case 3: The prediction is equal to the target. In this case, no update is required.
Logistic Regression
Consider the classic binary classification problem, where the target
variable
A common choice is to use the Bernoulli distribution
as the probabilistic assumption. Here we assume
where
By taking the derivatives of the log-likelihood, we can get almost
the same update rule as linear regression. Let
To derive a larger scale of models with the elegant update rule
Generalized Linear Models
Overdispersed Exponential Family
Overdispersed exponential family is a generalization of exponential
family, with a dispersion parameter
Similar to the exponential family, it has the following properties:
Property 1:
Property 2:
Property 3:
Property 4:
Note that these properties still hold no matter whether the probability distribution is continuous or discrete.
From my point of view, though overdispersed exponential familiy is
more flexible compared to the ordinary exponential family as it involves
the dispersion parameter
Introduction to GLMs
We begin with the linear predictor
Then, we need probabilistic assumpsions about the conditional
probability of the target
And how do we connect
Because using a canonical link function is a common choice(though counterexamples do exist), we will only focus on models using canonical link functions.
The figure below shows the relationships between
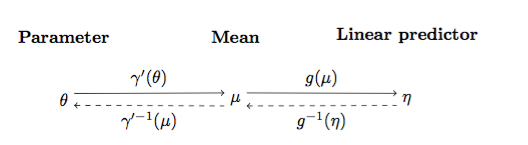
Note that
So what is the task of the model? It should compute the linear
predictor
It can be proved that the update rule for any generalized linear model using gradient ascent is always the following:
Linear Regression
As I mentioned above, the probabilistic assumption is the normal distribution, which is in the overdispersed exponential family:
As
So
Conclusion: For a generalized linear model with normal
distribution as the probabilistic assumption, ordinary linear regression
model with
Logistic Regression
In binary classification tasks, the probabilistic assumption is the Bernoulli distribution, which is also in the overdispersed exponential family:
Let
Take the derivative of
Which is the logistic function.
Conclusion: For a generalized linear model with Bernoulli
distribution as the probabilistic assumption, logistic regression model
with
Softmax Regression
In the end, we are going to solve classification tasks with any
number of classes (the target
The probability distribution we are going to use is
multinomial distribution (with
We can show that it is still in the overdispersed exponential family.
where
So
By setting
References & Resources
Wikipedia: Generalized Linear Models
Stackexchange: Does log likelihood in GLM have guaranteed convergence to global maxima?